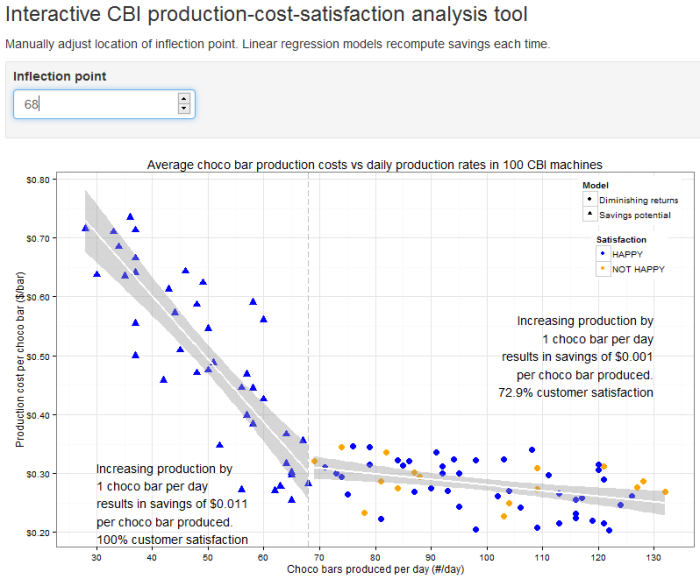
Benford’s Law: the principle that in any large, randomly produced set of natural numbers, such as tables of logarithms or corporate sales statistics, around 30 percent will begin with the digit 1, 18 percent with 2, and so on, with the smallest percentage beginning with 9. The law is applied in analyzing the validity of statistics and financial records. (from Google)
Benford’s Law can be used to detect anomalous results. Detecting anomalies is important in tax, insurance and scientific fraud detection.
In this example we are analyzing daily sales data from 11 Widgets Inc. stores. The board suspects some stores might be fabricating sales numbers. The only way to prove it is via a full audit of a store’s accounts. Auditing is expensive and so the board asked me to identify one store to audit.
We have 365 days of sales data for each of 11 stores – the data can be viewed here. In R I used the substring function to get the first digit from every day of sales for every store – full R script available here. Not every first digit distribution follows Benford’s Law but many do. It was clear from the plots that Benford’s Law was applicable on this occasion.

By plotting the observed distribution of first digits for daily sales from each store against the expected distribution we can identify which store veers furthest from the expected distribution. Visually, we can see that the sales numbers from Store K might be worth auditing.
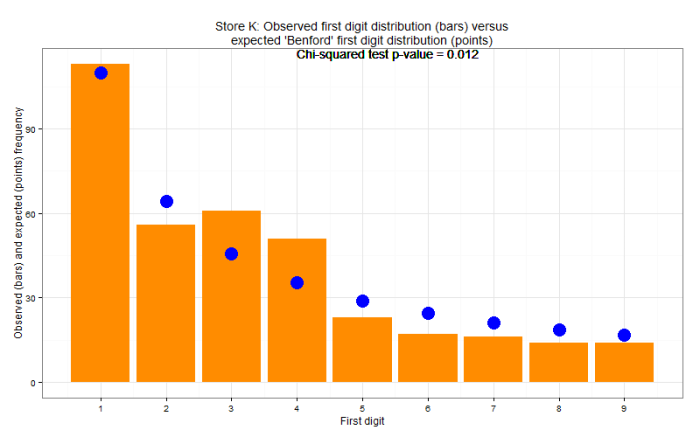
To augment this analysis and provide a more objective output a chi-squared test was carried out for each store. The chi-squared test is used to determine whether there is a significant difference between the expected frequencies and the observed frequencies. A lower chi-squared test p-value indicates a more anomalous distribution of first digits. Store K was audited and eventually they admitted to randomly generating sales numbers for many days during the year.
Note that disagreement with Benford’s Law does not prove anything. It merely offers a hint. A full audit of Store K was still necessary to prove any wrongdoing.
In this example we saw how data analytics identified which store was most likely to be the culprit thus avoiding audits of multiple stores. That’s what good analytics is about – the art and science of better.